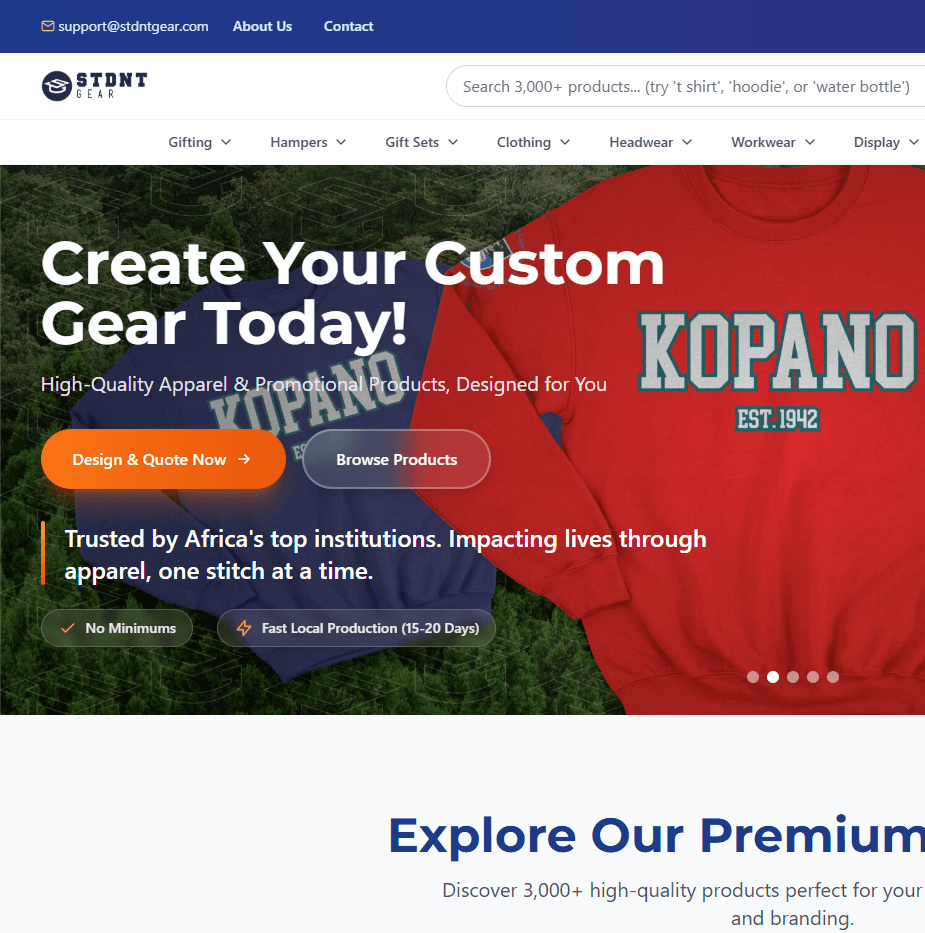
The problem
Schools, sports clubs, and corporate teams that want branded apparel — varsity jackets, team kits, event T-shirts — typically get a price the slow way: email a supplier, wait for a quote, go back and forth on quantities and print positions, wait again. There is no self-service way to browse a real catalogue, place a design on a product, and see a defensible price before committing.
STDNT GEAR replaces that loop with a platform where a customer picks a product, customizes it, and generates a priced quote themselves — while staff retain manual control over final pricing and approval, since custom print jobs still need a human sanity check before an invoice goes out.
Role & scope
I was the only engineer on this product. That meant every layer — schema design, API contracts, third-party integration, frontend architecture, deployment — was one continuous decision space rather than a handoff between teams. Concretely, I:
- Designed the PostgreSQL schema (27 tables) from scratch.
- Built the Express REST API (~70 endpoints) and all business logic.
- Built the customer storefront (React) and a separate staff admin portal (React).
- Engineered a data-ingestion pipeline syncing the full product catalogue — 3,000+ products, prices, stock, and colour swatches — from a third-party vendor API into PostgreSQL.
- Deployed and operate the platform in production.
Architecture
Client layer
API layer
Data & external
Both frontends talk to the same API. The storefront handles discovery, customization, and quoting; the admin portal handles pricing review, invoicing, and catalogue oversight. A scheduled ingestion job keeps the PostgreSQL catalogue in sync with the vendor's product API, since STDNT GEAR doesn't manufacture or warehouse stock itself.
Key engineering decisions
Vendor catalogue ingestion pipeline
The vendor API returns thousands of products with nested variants, prices, stock, and colour swatches. Naively inserting everything concurrently caused PostgreSQL deadlocks under load, and a single failed record could kill the whole sync.
- Single-threaded sequential inserts — safe but far too slow for a full catalogue refresh.
- High concurrency (10+ parallel batches) — fast, but frequent deadlocks on shared indexes.
- Smart batching with capped concurrency and per-operation retry.
Grouped products into batches of 50 (partitioned to reduce key overlap), capped concurrency at 2 in-flight batches, and wrapped every write in deadlock-aware retry with exponential backoff.
A full catalogue sync is slower than it could theoretically be, but it runs unattended and self-heals from transient PostgreSQL deadlocks instead of failing the whole job.
Server-authoritative pricing
Quotes and invoices involve price adjustments (staff discounts, corrections). If a client ever computed or held the authoritative total, a tampered request could change what a customer owes.
- Trust the price the client submits with the quote.
- Recompute and lock the total server-side whenever a quote is priced or converted to an invoice.
Every quote total is calculated and locked server-side. Staff-applied adjustments are stored as discrete line items, not baked into a single mutable total, so invoice history stays auditable.
More server-side computation and stricter API contracts, in exchange for pricing integrity that can't be bypassed from the client.
Caching strategy for the product catalogue
Category trees and multi-facet product filters (brand, gender, material, fit, price) get slow at scale if every filter click hits PostgreSQL with fresh joins.
- No caching — simplest, but filter interactions get sluggish as the catalogue grows.
- Cache everything in Redis from day one.
- Layer caches by volatility: in-memory for near-static data, React Query for per-user UI state, Redis reserved for cross-instance needs.
Cache the category hierarchy in server memory with TTL + explicit invalidation on writes, run facet-count queries in parallel rather than sequentially, and let React Query handle client-side staleness.
In-memory cache doesn't survive a restart or share state across multiple server instances — acceptable for current scale, with Redis already integrated as the upgrade path.
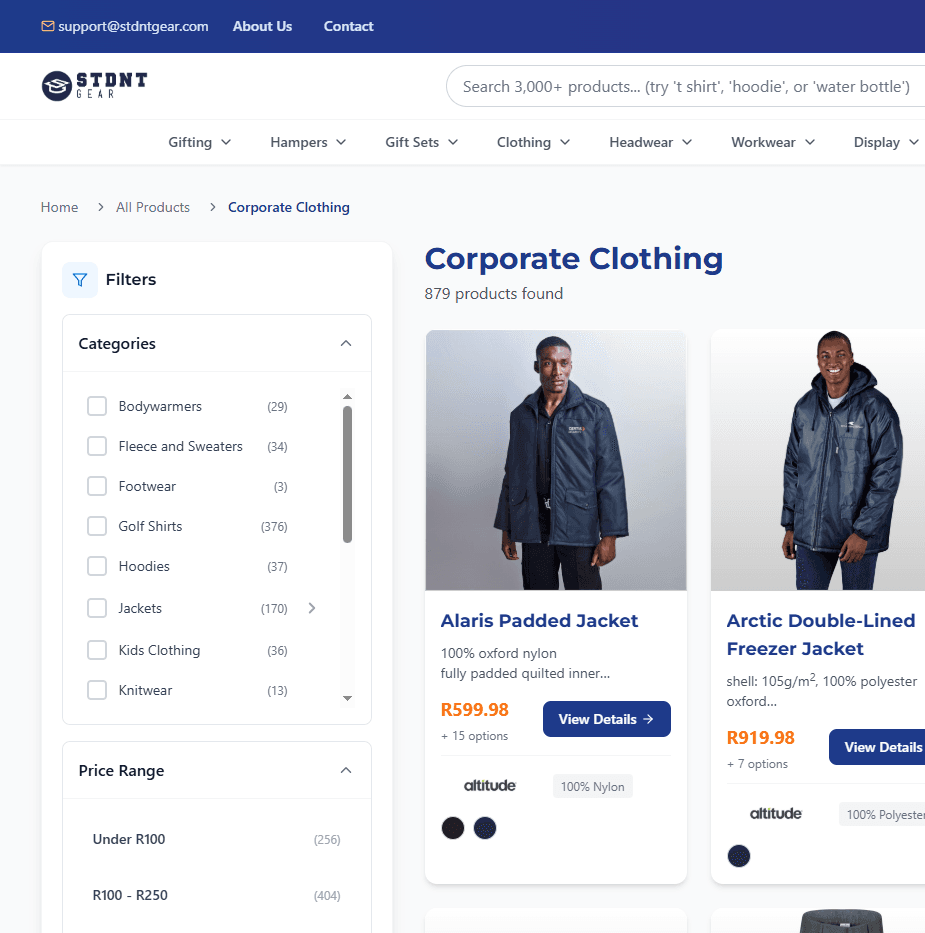
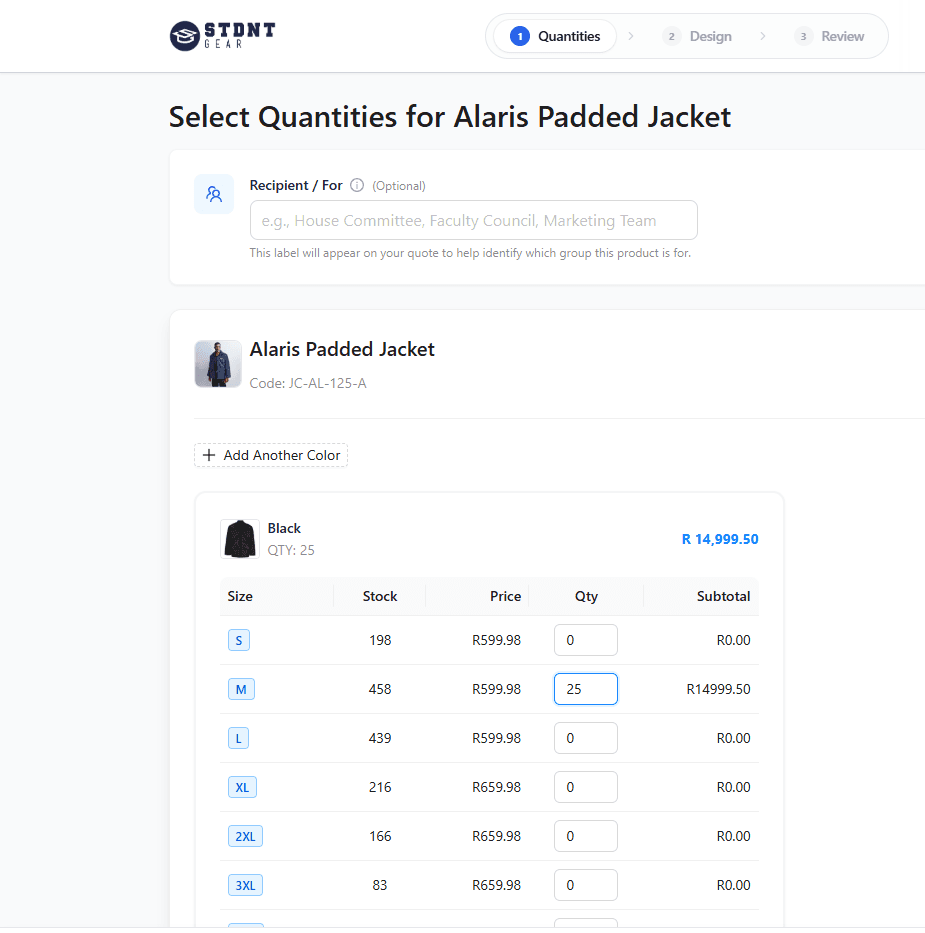
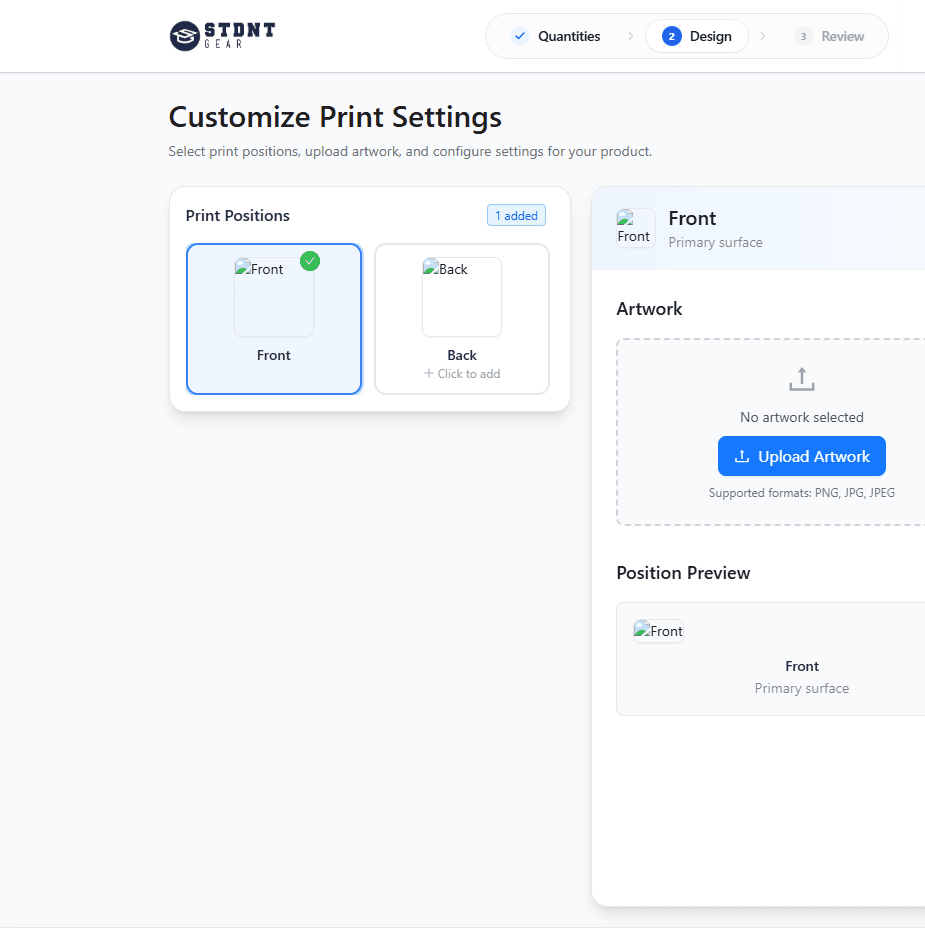
The quoting flow, in practice
The catalogue view below is the direct product of the caching decision above — multi-facet filters (category, price, stock) running against 879 products in this category alone, with facet counts computed in parallel rather than serially.
Security & auth
Authentication is JWT-based with short-lived access tokens and HttpOnly refresh tokens, plus optional Google OAuth. Beyond the basics, I added account lockout after repeated failed logins, audit logging of authentication events, and rate limiting on auth endpoints — the kind of hardening that matters once a platform holds real customer accounts and payment-adjacent data, even without a payment gateway yet.
Challenges
The hardest problems weren't in the UI — they were in keeping a large, frequently-changing external catalogue consistent with an internal schema that also has to support fast filtering. Deadlocks under concurrent writes (solved above), keeping category and price caches from going stale after a sync, and designing a quote data model flexible enough for arbitrary print positions and personalization without becoming an unstructured blob were the recurring hard problems.